
An Ecosystem Examined
The fundamental viability of any solution is tied to the underlying economic metrics that both support the creation and ensure the longevity of said solution. The advent of blockchain technologies has allowed a diverse range of virtual currencies to be brought to the fore of the burgeoning industry — yet it is often questioned as to the sustainability of such virtual economies.
The requirement for a virtual currency is a significant consideration when building a new product ecosystem, especially within the realm of blockchain solutions where custom currencies are easily minted. The critical factor in determining the requirement for a custom currency, irrespective of the blockchain used, is how the underlying technology contributors and consumers seek to exchange value and the mechanics of the associated virtual economy.
This exchange of value is at the core of the Koios ecosystem — specifically the ability for developers, AI constructs, crowdworkers and consumers to freely interact without the requirement for an intermediary.
To create an independent, autonomous economy of value a custom token is required; this allows the platform the flexibility to dynamically manage the reward vs effort metrics used for incentivization when performing actions within the ecosystem.
When taking into consideration the inherent challenges when creating machine learning algorithms — the first problem to be rectified is the availability of data sources. With this in mind, it became apparent that a “data ecosystem” is required. The ability to source sizable data sets of any type to programmatically train an algorithm can be laborious and costly. Dependent on the type of algorithm that is being created, a viable dataset that has been pre-labelled and validated can be onerous to create or source at scale.
The “Data Ecosystem” is at the core of the Koios platform and thus the integrity, availability and consistency of data is of the utmost criticality to the success of the project. To ensure that the types, scale and quality of data is available to developers the data ecosystem will leverage an automated, decentralized incentivisation model for data publishing, collection and refining.
For the purposes of simplifying the data labelling process for developers, the ecosystem will incentivise crowd workers to participate in the network by allowing them to both contribute and label data.
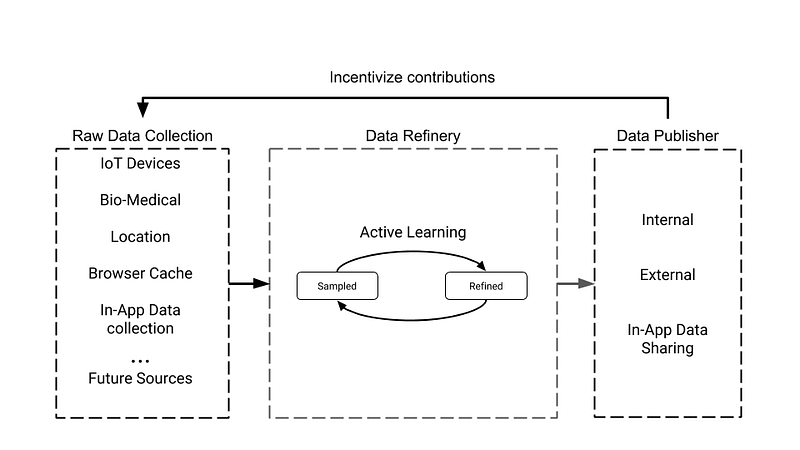
It is this model that will allow the Koios ecosystem to source data from numerous repositories in the formative and iterative phases of data collection. The figure above shows three actors; the data publisher, the data collector and the data refiner. A data publisher is a source of data who has consented to participate in the network by contributing their datasets in return for an exchange of value, namely Koios Tokens. A data collector is an autonomous entity, namely an API or AI construct, responsible for the ingestion of published data. The data refiner is a special case of semi-supervised machine learning in which a learning algorithm is able to interactively query the user (or some other information source) to obtain the desired outputs at new data points.
The resultant output is then shared to applications, AI models or developers. This iterative approach to data sourcing will sanitise and autonomously ensure the integrity and uselessfulness
of the data under management. Publishers will be rewarded commensurately with the volume, quality and usefulness of data.
The second use case for the platform is that of data labelling; namely the requirement for human intervention within the process of supervised machine learning. Consider the following example:
“An AI developer is looking to refine an algorithm that increases the chances of detecting cancer in the early stages of development. To complete such a task there is a requirement for a volume of medical images that both depict the presence of cancer as well as the absence of it. A series of positives and negatives for the machine to analyse and develop a pattern, per se. The larger the data set to train the algorithm, the more likely the algorithm has of becoming a viable detector of malignant tumours.”
The key takeaway from such an example is the requirement to have a series of images that have been labelled as both positive results (i.e. contains a tumour) and negative results (i.e. does not contain a tumour) for use in ML training epochs.
For reference, an epoch is a measure of the number of times all of the training vectors are used once to update the weights. For batch training all of the training samples pass through the learning algorithm simultaneously in one epoch before weights are updated. The higher the number of samples (i.e. a labelled image) the more accurate the model becomes.
In order to successfully train a supervised machine learning model volumes of data that have been pre-labelled need to exist. Some datasets are pre-labelled autonomously (e.g. medical imagery) whilst others cannot be automatically labelled due to the nature of the data (e.g. determining what is a cloud vs a snow-capped mountain in weather imagery).
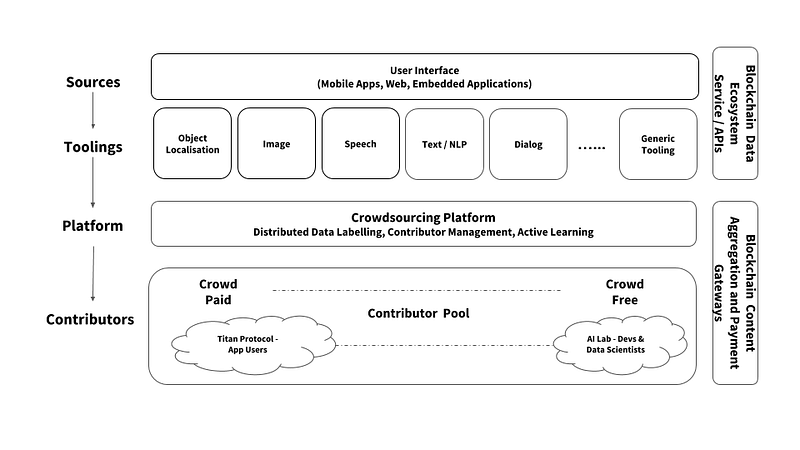
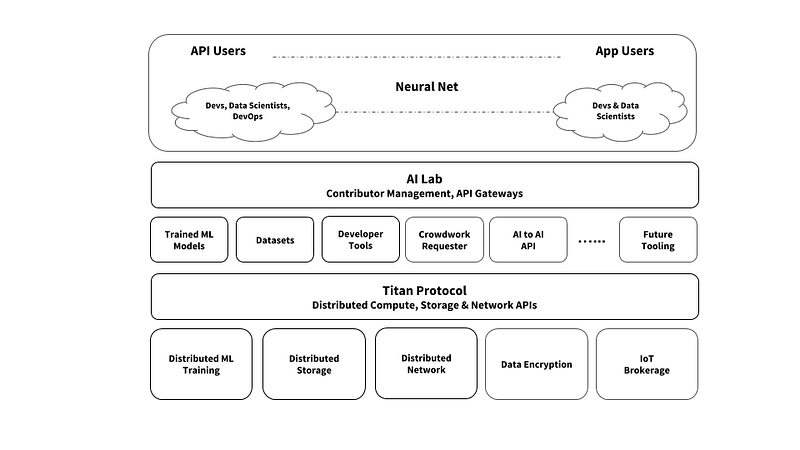
The combination of algorithm creation, data sourcing, data labelling and incentivization leads to the foundational logical architecture for the ecosystem — namely:
- The user interface required for accessing the platform
- The API tooling required to contribute and label datasets
- The crowdsourcing platform mechanics for content aggregation
- The blockchain integration APIs and constructs required for the incentivisation of the contributor pool
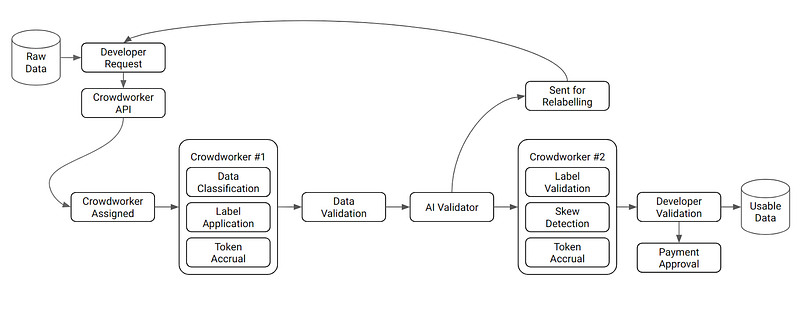
A simplified view of the process by which a developer can request data labelling services via the scheduling API is as follows:
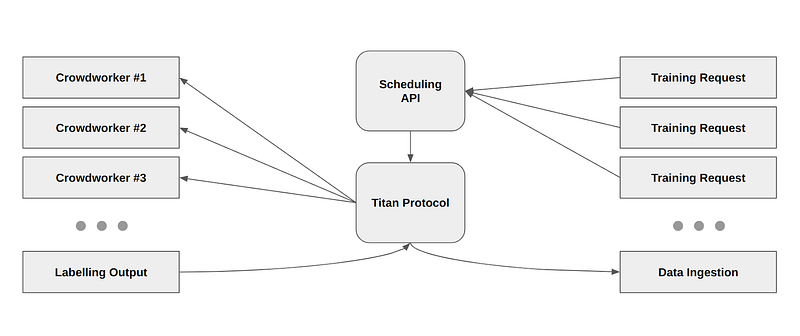
With a foundational data ecosystem in place, a further iteration inclusive of the development, crowd computing and marketplace integration modules are the next step in evolving the logical architecture.
The development module provides a number of frameworks and runtimes in which the developer can code, test, iterate and publish AI content. The predominant focus area will initially be for Tensorflow; the most popular framework on the market today. As Tensorflow is a pre-existing construct we will not provide any focus in this publication but will instead focus on the complementary offering within the product ecosystem — distributed machine learning powered by a decentralized network of computing devices (e.g. PC, Mac, smartphone, tablet, etc).
For establishing the distribution of training data to these devices, each network node passes sample data of size ‘x’ to a decentralized cluster of master nodes which act as the data aggregator and messaging bus. To achieve this, a “bittorrent aggregate” is performed where each master node passes control messages from one node to another in parallel as the data stream is encapsulated, checksummed and deduplicated. Once assembled, the data is then ready for distribution to network participants for ingestion, processing and return.
Any device with an idle computational cycle can become a network participant; an untrained algorithm is distributed to the network device along with the training data and a resultant epoch is completed and the results are aggregated, normalised and added to the overall results — should the network participant disconnect, subsequent epochs are performed on other devices until the desired number of training epochs are completed.
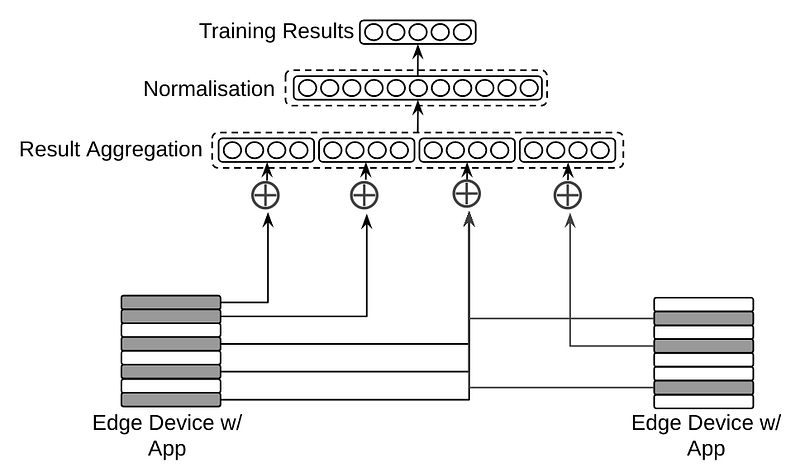
The resulting model is then stored and ready for review by the initiating developer and network participants are then rewarded for the usage of their processing power.
With the logical functionality of network incentivization, data collection, data labelling and distributed computation in place the final consideration is the way in which network participants can perform an exchange of value for proprietary digital assets (e.g. trained ML models, API access to ML, labelled data sets, etcetera).
A primary reason blockchain was chosen as a foundational technology for the ecosystem is the ability to create a virtual economy and digital currency capable of autonomously exchanging value between network participants without the requirement of an intermediary, censorship or arbitration.
Developers, crowd workers and business consumers will access the system via either a browser-based application or a smartphone application (i.e. iOS & Android). A series of APIs will conduct interaction between the blockchain and other ecosystem components.
Koios. An ecosystem of products to build, buy and deploy AI.#koios #democratiseAI #crypto #blockchain #ico #tokensale #cryptotrading #hodler pic.twitter.com/zuQhTKI8qa
— Koios (@koiosai) May 4, 2018
If you would like to have your company featured in the Irish Tech News Business Showcase, get in contact with us at [email protected] or on Twitter: @SimonCocking
More about Irish Tech News
Irish Tech News are Ireland’s No. 1 Online Tech Publication and often Ireland’s No.1 Tech Podcast too.
You can find hundreds of fantastic previous episodes and subscribe using whatever platform you like via our Anchor.fm page here: https://anchor.fm/irish-tech-news
If you’d like to be featured in an upcoming Podcast email us at [email protected] now to discuss.
Irish Tech News have a range of services available to help promote your business. Why not drop us a line at [email protected] now to find out more about how we can help you reach our audience.
You can also find and follow us on Twitter, LinkedIn, Facebook, Instagram, TikTok and Snapchat.